A common metric enforced among enterprise software projects is minimum code coverage. The motivation for this mandate is that with a high enough requirement, we should have confidence that our features are well-tested. After seeing numerous production defects that seem to defy the promised safety net of our code coverage gate, it’s time to rethink what gives us confidence in our code.
Test-Driven Development gives us that confidence and more while also giving us a high coverage metric as a side effect. Before I explain why TDD is the solution, let me illustrate why code coverage alone doesn’t already solve our problems.
Code coverage is not a measure of well-tested code but is a tool for detecting missing testing practices.
Not a measure of well-tested code
It doesn't account for and can lead to insufficient tests/assertions
The presence of a high code coverage number tells us only that the lines of code were executed, but it says nothing about whether their result was measured in any meaningful way. It’s possible that only a subset of tests assert anything correctly– or at all. Additionally, the existence of a code coverage requirement with no other emphasis on testing might contribute to even more bad tests being written.
Writing valuable tests requires mental effort. If testing is not a priority, developers often think about test coverage only when trying to finish a story. In many cases, all the production code for a feature has been written, but when trying to make a pull request, the code coverage check fails. When this happens, whether due to a deadline or just a sense of urgency to wrap up the story, tests that execute every line are hastily written. Perhaps the good intent to go back and add valuable assertions is there, but it’s easy to forget. By writing tests in this way, we may end up with lines of code executed against missing or bad assertions, thus giving us false positives in terms of feature functionality.
These are more dangerous than missing tests.
Example
Consider this rudimentary example of a login tracking system:
class ActiveUserTracker {
constructor() {
this.activeUsers = [];
}
login(userName) {
this.activeUsers.push(userName);
}
}... test("login", () => { const subject = new ActiveUserTracker(); subject.login("userA"); expect(subject.activeUsers.length).toBe(1); }); ...
Great, I have a simple, working login tracker. 👍
Now, let’s say I want to add a feature that prevents duplicate login entries:
class ActiveUserTracker {
constructor() {
this.activeUsers = [];
}
login(userName) {
// if no active users, add them to the list of active users
if (this.activeUsers.length === 0) {
this.activeUsers.push(userName);
return;
}
// check to see if they are already an active user and ignore
// otherwise add them to the active users list
for (const activeUser of this.activeUsers) {
if (activeUser === userName) {
return; // introduces a bug that allows duplication
} else {
this.activeUsers.push(userName);
}
}
}
}
...
// Disclaimer: This code intentionally leaves room for improvement for the sake of example
Adding a backfilled test for code coverage:
...
test("login", () => {
const subject = new ActiveUserTracker();
subject.login("userA");
expect(subject.activeUsers.length).toBe(1);
});
test("login prevents duplicate entries", () => {
const subject = new ActiveUserTracker();
subject.login("userA");
subject.login("userB");
subject.login("userB");
expect(subject.activeUsers.length).toBe(3); // should be expecting 2
});
...
----------------------|---------|----------|---------|---------|-------------------
File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s
----------------------|---------|----------|---------|---------|-------------------
All files | 100 | 100 | 100 | 100 |
activeUserTracker.js | 100 | 100 | 100 | 100 |
----------------------|---------|----------|---------|---------|-------------------
Oops– My implementation isn’t quite right, and neither is my test. I still have 100% code coverage, but my new test has a bad assertion. My test should be expecting 2 entries, not 3, yet it still passes. This false positive hides the fact that the implementation code still allows duplicate entries. I backfilled my test, so I never got a chance to see that it was incorrect. If I had written this test via TDD, I would have known this was a bad test because it passed without adding any implementation code. TDD protects you from this situation by mandating that you start with a failing test.
As a disclaimer, TDD doesn’t stop you from accidentally writing bad tests. It is a tool, and when followed correctly, gives us confidence that the tests we’re writing are actually connected to and testing production code in some way.
It doesn't capture the value of tests vs cost
The Pareto Principle states that:
"80% of consequences come from 20% of causes"
This hypothesis has interestingly been observed to be true across a number of domains, including software engineering. We can often observe it in codebases, with a majority of the testing complexity existing in a small percentage of the code.
I generally recommend not spending lots of time on tests that don't add confidence and come at a high cost. Forcing a development team to spend lots of time chasing a specific code coverage percentage for little confidence in return can really take the wind out of the project's sails. Weigh the development costs against the code's value/impact before sinking too much time into it. If you write code using Test-Driven Development, you will end with more testable code anyway.
By following TDD, we naturally write production code that is easier to test. Difficult tests to write are often a clue that our implementation is overly complex and should also be simplified. Now we see another benefit of Test-Driven Development: Cleaner, simpler production code. Easily testable code is often simpler code.
The Dynamic nature of code distribution in our codebase
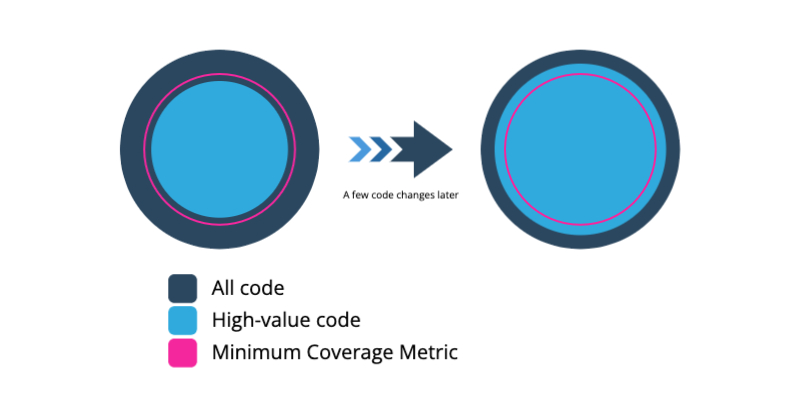
Our testing methodology should adapt to changes in the codebase over time, automatically adjusting to testing needs. Where 83% line coverage today might account for all of the high-value, testable code, 85% might be needed tomorrow after more code is added. Arbitrarily choosing a number is likely going to miss the ever-changing distribution of high-value code in our codebase.
A tool for detecting bad testing practices
The presence of code coverage may not tell us much about the quality of our test suite, but the lack of code coverage does shine a light on potential gaps in our testing practices. In particular, it reveals untested code and the need for a practice change, not a metric increase.
Untested code
This is the obvious one. Ideally, most of the code in our codebase contributes to functionality in some way, thus, there should be a test for most things. While a high number doesn’t prove we have valuable tests, a low enough number indicates that we may be missing some valuable tests somewhere.
The need for a practice change, not a metric increase
A rising code coverage rate doesn’t always correspond to a proportional decrease in the rate of defects. This discrepancy highlights that a single number can’t replace good testing practices and that testing should instead be thought of as a first-class citizen, not an add-on. If our coverage has dropped to an unacceptable level, we should ask ourselves what practices (or lack thereof) allowed it to drop and address the cause.
Test-Driven Development as a solution
Covering the codebase with meaningful tests takes significant effort. Many of the problems above are caused by attempting to backfill tests after the code is written. This is where Test-Driven Development really shines, and as a perk, we will end up with a high coverage number as well. By following a red-green-refactor cycle, we ensure a meaningful connection between our tests and our code.
Test-Driven Development enables our development team in other ways, as well. In addition to code coverage, some of the benefits of TDD include:
- A codebase that is optimized for change
- Consistent speed of development
- Ease of refactoring
- Living documentation of functionality
- A better understanding of how our code works
- Easier developer onboarding
In order to build a robust test suite that succeeds in giving us confidence in our production code, good testing practices/discipline should be valued on teams, reinforced when they fall behind (potentially evidenced by low code coverage), and regarded as a first-class citizen. TDD builds this priority into the way the team works and removes the need to track things like code coverage.
Pulling it together
Code coverage is most useful as an indicator when it drops, indicating a problem. We need to replace it with something that satisfies the goals of code coverage while also increasing our confidence in the codebase overall. Stories shouldn't call out a minimum coverage percentage, but instead, the team should agree to follow a testing practice that mitigates the need for it. I see value in code coverage mostly as an indicator of whether or not testing practices are an accepted team norm, triggering larger team discussions on the value of testing.
In closing, I would like to reiterate that coverage can still be a useful metric, but only when paired with an effort to make testing a first-class citizen. It should not replace good testing practices like Test-Driven Development. Instead, use it as a tool to move your team towards better testing practices, and perhaps code coverage will become a conversation that doesn't even need to happen.
Focused Labs Can Help
If your team could use some expert guidance in adopting Test-Driven Development, complete our Contact Us form, to discuss how the experts at Focused Labs can help.