Introduction
Are you searching for an exceptional framework to build your own custom AI applications? I would highly recommend Langchain. With their latest update using Langchain Expression Language (LCEL), they’ve created a framework for developing applications powered by language models. Their libraries support multiple features right out of the box such as:
- streaming
- asynchronous support
- batch support
- parallel execution
- retries and fallbacks
- dynamically routing logic based on input
- output parsing
- message history
Step-by-Step Upgrade
Here’s how we upgraded our old RAG AI Application to use LCEL. Visit our GitHub repository to deep dive into the code. You can learn more about the architecture of our old application in this blog post. To upgrade, I followed the RAG tutorial on LangChain's documentation.
1. Understand the Refactor
LCEL uses components to create chains. AI-powered apps are not just language models, often they use multiple supporting components to create that magical user experience (with more accurate results).
So here are 3 key concepts:
- LCEL is similar to a Linux pipe functionality, with dictionary keys linking everything.
- The
Runnableinterface is central. - Outputs need to match the input schema of the next
Runnable.
2. Whiteboard My Plan
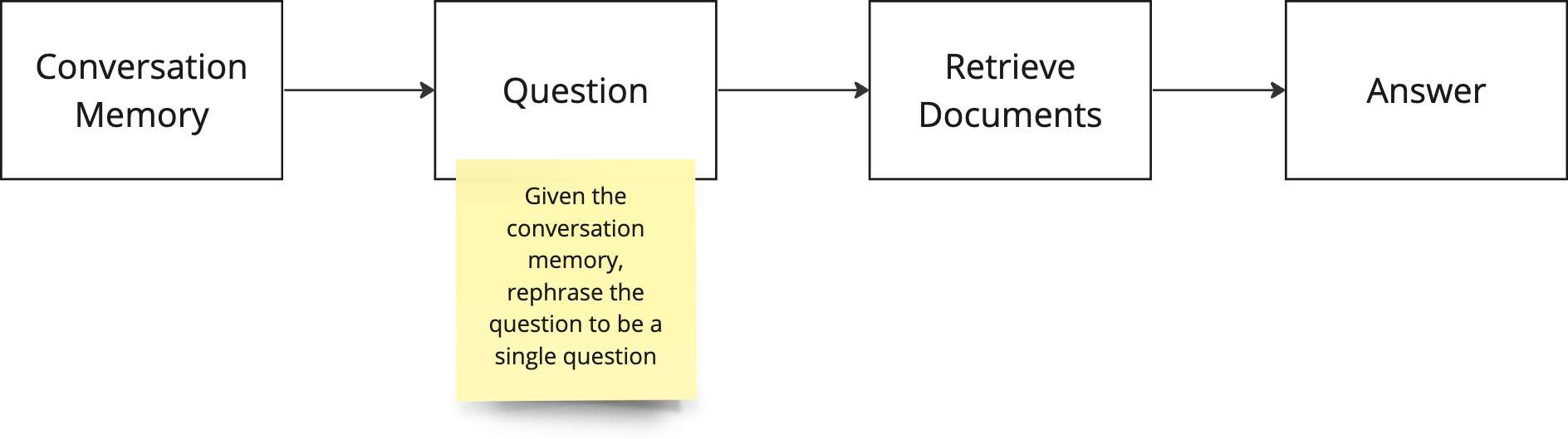
I started with a quick whiteboard diagram to visualize the components needed: a question, a way to retrieve documents, and an answer. While this may seem redundant, creating a basic architecture diagram points out the necessary pieces of code - keeping me on track when it’s easy to get distracted in a see of tutorials.

3. Take some code for a test drive.
The goal in this step is to understand the code with minimal overhead. I used a Jupyter notebook for speed and flexibility - unit tests or other small scripts are other great tools to quickly spin up code.
As I followed the tutorial on LangChain, I was quickly able to see the importance of threading the dictionary keys together: "question", "docs", "answer", etc.
In the code snippet below, it’s easy to trace the keys through the chain. So, when I use answer in my full chain, I will need to make sure that the output of the component right before contains “docs” and “question” keys.
from config import CHAT_MODEL
from langchain.prompts import ChatPromptTemplate
from langchain.schema import format_document
DEFAULT_DOCUMENT_PROMPT = PromptTemplate.from_template(template="{page_content}")
def _combine_documents(
docs, document_prompt=DEFAULT_DOCUMENT_PROMPT, document_separator="\\n\\n"
):
doc_strings = [format_document(doc, document_prompt) for doc in docs]
return document_separator.join(doc_strings)
final_inputs = {
"context": lambda x: _combine_documents(x["docs"]),
"question": itemgetter("question"),
}
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
ANSWER_PROMPT = ChatPromptTemplate.from_template(template)
answer = {
"answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(temperature=0, model=CHAT_MODEL),
"docs": itemgetter("docs"),
}
4. Translate to Python Scripts
Once the basics worked, I translated the notebook into python scripts with a Class architecture for clarity and alignment with my initial diagram.
💡Tip: Remember, Python doesn’t always enforce exact type safety by default. So, keep in mind that you want to work with Runnable (or variations of this interface) and not dicts or Unions.
I extracted the vector store into another class for seamless swapping between vector stores (for example, Redis vs Pinecone).
class Chain:
def __init__(self, vector_store):
self.vector_store = vector_store
self.question = create_question_chain()
self.retrieved_documents = retrieve_documents_chain(self.vector_store)
self.answer = create_answer_chain()
self.complete_chain = self.question | self.retrieved_documents | self.answer
5. Iterate
Adding new components to the chain becomes clear and intuitive. I wanted to include memory conversation in my flow. So, I returned to the whiteboard for a visual outline of where I was going.
Then, I was able to use Langchain’s memory components for easy integration. The result felt clean and elegant.
💡Tip: Currently, saving answers into memory is not be automatic. Thankfully, Langchain’s documentation is pretty good. Here’s just a friendly reminder from one developer to another to read the documentation 🙃.
class Chain:
def __init__(self, vector_store):
self.vector_store = vector_store
self.loaded_memory = load_memory_chain()
self.standalone_question = create_question_chain()
self.retrieved_documents = retrieve_documents_chain(self.vector_store)
self.answer = create_answer_chain()
self.complete_chain = self.loaded_memory | self.standalone_question | self.retrieved_documents | self.answer
def save_memory(self, question: str, answer: str, session_id: str):
get_session_history(session_id).save_context({"question": question}, {"answer": answer})
Biggest benefits of LCEL
- Easy composability. Adding new components is much simpler.
- Increased visibility. You can see the things that matter more. You can see intermediary steps, which helps to debug. You can see prompts (and other prompts aren’t burried in library code).
- Elegant solution to handling input and output parsing.
For example, you can see the amount of brittle parsing on the left that was in our RAG application, and now, on the right, using LCEL, it’s only a few lines of code.
# Before LCEL
response = self.agent_executor.run(input=user_input)
if is_answer_formatted_in_json(response):
return response
return f"""
"""
except ValueError as e:
response = str(e)
response_prefix = "Could not parse LLM output: `\\nAI: "
if not response.startswith(response_prefix):
raise e
response_suffix = "`"
if response.startswith(response_prefix):
response = response[len(response_prefix):]
if response.endswith(response_suffix):
response = response[:-len(response_suffix)]
output_response(response)
return response
def _parse_source_docs(q_and_a_tool: RetrievalQA, query: str):
result = q_and_a_tool({"question": query})
return transform_source_docs(result)
def output_response(response) -> None:
"""
You may be wondering why aren't we streaming the response using the openai completion API
This is currently in beta in the langchain library, I will update this example
to showcase this as implementation details may change
Since it's flagged as beta adding it here may cause confusion as most
likely it will be changed again within a few weeks
For now output_response will simulate streaming for the purpose of illustration
Args:
response: text output generated by ChatGPT
"""
if not response:
print("There's no response.")
else:
print(response)
print("-----")
def is_answer_formatted_in_json(answer):
try:
json.loads(answer, strict=False)
return True
except ValueError:
return False
def format_escape_characters(s):
return s.replace('"', '\\\\"').replace("\\n", "\\\\n")
def transform_source_docs(result):
formatted_result_string = format_escape_characters(result["result"])
if 'source_documents' in result.keys():
return f"""
"""
return f"""
"""#
# After LCEL
result = self.chain.complete_chain.invoke(
{"question": question.text, "session_id": question.session_id, "role": question.role})
answer = result["answer"].content
sources = []
for doc in result["docs"]:
source_url = doc.metadata['URL']
sources.append({"URL": source_url})
Conclusion
Embracing LCEL with LangChain isn't just about accessing new features; it's about leveraging a more intuitive, flexible, and visible development experience. Whether you're eager to integrate the latest AI tech or streamline your debugging process, LCEL offers the advanced tools and capabilities you need to excel in the fast-evolving world of development. Dive in and transform your AI application development with LangChain today! Happy coding!