Are you interested in how AI chatbots work? Do you want to build your own but don't know where to start? In this post, we're going to break down the process. We'll walk you through the basics of how to leverage Large Language Models (LLMs), specifically for a chatbot designed for a specialized subject or field. We'll explain how you get the bot ready to answer questions by feeding it the right data, and then how it uses that data to answer a user's queries. Whether you're a programmer who wants to learn more about chatbots, or just curious about the technology behind the chat interfaces we often interact with, this post is intended to provide a helpful starting point.
The construction of a custom AI chatbot involves primarily two processes:
- Preparing the custom data
- Querying the custom data as per the user's request.
At a high level, when a user asks a question, we take their prompt, and reference a bespoke database to find information that is most similar to their question. Then, we reword the raw search results to elegantly answer the user’s original question. The database of custom data is configured in such a way to make it easy to search for what pieces of text are most related to the user’s question.
Implementation Details
For this project, my team and I developed a smart AI chatbot specifically tailored for the Focused Labs website. The objective was not to create a simple chat interface, but rather a holistic 'Knowledge Hub' and leverage the power of natural-language models. An AI-based Enterprise Knowledge Hub has the capability to synthesize multiple diverse information sources into a single, accessible resource. The primary goal for this AI chatbot, thus, was to create an intelligent entity capable of seamlessly integrating a vast array of information.
In the creation of our chatbot, we leveraged a combination of specific tools, models, and data sets. Here's a simplified breakdown of our configuration:
- Python Libraries: To facilitate the development process, we incorporated two Python libraries: Langchain and Llama Index.
- Chat Model: For the core conversational abilities of our chatbot, we used OpenAI's gpt-3.5-turbo.
- Vector Embedding Model: To transform our data into a format that can be understood and manipulated by our chat model, we utilized OpenAI's text-embedding-ada-002.
- Vector Database: We chose Pinecone as our vector database. This is where we store and query the vector representations of our data.
- Data Sets: Our data originates from two main sources:
- Our internal Notion wiki, which provided a robust set of data capturing our specific domain knowledge.
- Our public website, Focused Labs, which gave our chatbot a wider context and understanding of our company's public-facing information.
Having detailed our chatbot's fundamental setup, we'll now explore the crucial process of preparing our proprietary data for search and retrieval. This process happens before users ask questions of our chatbot, and is the best technique for building an accurate question-and-answer AI conversationalist.
Prepare the proprietary data for search and retrieval.

- Import Data: Start by importing your custom data into your application. This data can be any form of text. Llama Hub has a lot of open source data loader libraries that will make importing data simple and easy. For our use case, we imported pages from our Notion wiki, and we used the Notion loader to import them. We also leveraged the Beautiful Soup Website Loader to scrape our website for public-facing information. These two libraries were extremely easy to plug and play, but unfortunately are limited to only text information.
- Clean Data: Next, you’ll want to clean your data for improving accuracy, efficiency, reliability, and quality of insights. The task of refining your data can be as straightforward as eliminating superfluous elements such as additional whitespaces, graphics, and emojis. However, this process can escalate in complexity, becoming a time-intensive and energy-consuming task. We leveraged 3 simple data normalization methods in our python code: removing emojis, replacing contractions with their full-length counterparts, and remove superfluous punctuation and whitespace.
- Chunk and Tokenize Data: The cleaned data is then segmented into smaller "chunks". Think of these chunks as analogous to individual sentences from the PDF. These chunks are further broken down into "tokens", akin to the words or parts of words in a sentence. Tokenization is crucial as AI models operate at a token level. It's optimal to use the same tokenizer that your embedding model was trained on to ensure compatibility. Luckily, Llama Index creates the tokens for you. So, all you need to do is specify the number of tokens you want per chunk, and the library will handle the logic for you.
- Create embeddings: The tokens are transformed into vectors using an embedding model. Think of vectors like address labels for words. Each word is given a unique numerical 'address' or vector that helps a LLM understand what the word means and how it relates to other words. It's a way for computers to categorize and understand human language. They are able to use math to then measure how similar various words are to each other and thus map out the meaning of the word. Once again, Llama Index will handle the embedding logic for you. The library defaults to leveraging Open AI’s text-embedding-ada-002, which is industry standard.
- Add metadata: Valuable metadata, such as the original source of the data or the title of the document, is attached to these vectors. Metadata provides essential context leading to increased search-ability. It also helps to maintain data integrity of your chatbot by providing key information for tracking and auditing. We specifically added the source to our metadata, for easy verification of the information later on.
- Store Data: The vectors, along with the associated metadata, are stored in a vector database, ready to be queried when required. We used Pinecone - a managed native vector database. We started using a Docker-deployed instance of a Redis database, but we preferred Pinecone because of it’s managed feature. We also found Pinecone to produce slightly better results in a faster response time.
Query the custom data per the user’s input.
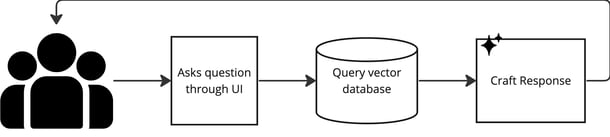
This process operates asynchronously to the first process. In its most simple form, generating a response to a user requires only 3 components.
- Question Input: Users interact with the chatbot via a user interface, which could be a web application built with React, a Python Command Line Interface (CLI), or any platform that meets your specific requirements. The user's question is sent directly to the vector database for processing.
- Database Search: The vector database performs a similarity search, identifying the vectors that are most similar to the input question. This finds the information that is most likely to answer the original question.
- Response Generation: The results from the vector database are combined with the original user question and fed into a language model. This model generates a human-like response that is contextually aligned with the question. This output is then sent back to the user.
While this basic flow works efficiently, it can only address queries related to the custom data. To enhance the versatility of the chatbot, consider integrating a chat engine.

By using a chat engine, you can integrate various components. It uses a language model to determine which actions to take and in what order. This provides a more interactive and user-friendly experience compared to directly querying the database, as the chat engine can provide additional context and guidance to the user.
Before sending a user’s question to a chat engine, I recommend adding it to a prompt template. Prompt templates leverage known industry-standard phrases to increase the quality of the AI model’s behavior. For example, a template could be, “You are a virtual assistant. Your job is to answer questions. If you don’t know the answer, say ‘I’m not sure.’ Don't try to fabricate an answer. Question: {user's question}”.
When configuring the chat engine, you can specify certain tools it can use to retrieve information. If the chat engine determines that it needs to use the vector database to answer a question, it will query the vector database accordingly. If it doesn't need to access the vector database, it will generate an answer directly. The chat engine also maintains memory of the chat session, which can be used for context in further conversation.
Here is a diagram showing what tools we use for our implementation.
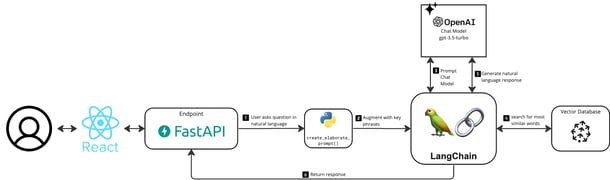
Langchain is the key tool of our flow. Its chat engine component, called an agent, facilitates the communication with the chat model and the vector database.
In conclusion, creating a domain-specific AI chatbot is a multi-step process that requires a solid understanding of both the underlying data and the intended user experience. While the processes we've discussed form the fundamental building blocks, the complexity can grow as you expand the chatbot's capabilities or deal with more diverse data.
But, don't let the complexity deter you. Mastering the basics forms a strong foundation upon which you can build more advanced features. As AI continues to shape the technological landscape, the skills and knowledge you gain in AI chatbot development will undoubtedly prove invaluable. Here's to you, embarking on your journey in the fascinating world of AI chatbots.
What’s Next
If you have an AI development project and would like some expert help from our Focused Labs consultants, complete our Contact Us form and we will have a human chat.